在AI大模型飞速迭代的当下,

一、痛点切入:为什么传统AI助手不够用了?

传统AI助手多采用“一问一答”的对话模式。以调用API生成回答为例:
传统AI助手调用方式:单次对话,无状态记忆def ask_traditional_ai(question): response = call_api(question) 每次独立调用 return response 返回单次回答,无后续规划能力
这种模式存在几个明显局限:一是
正是这些痛点,催生了Kimi向“智能执行体”的演进。
二、核心概念讲解:智能体集群(Agent Swarms)
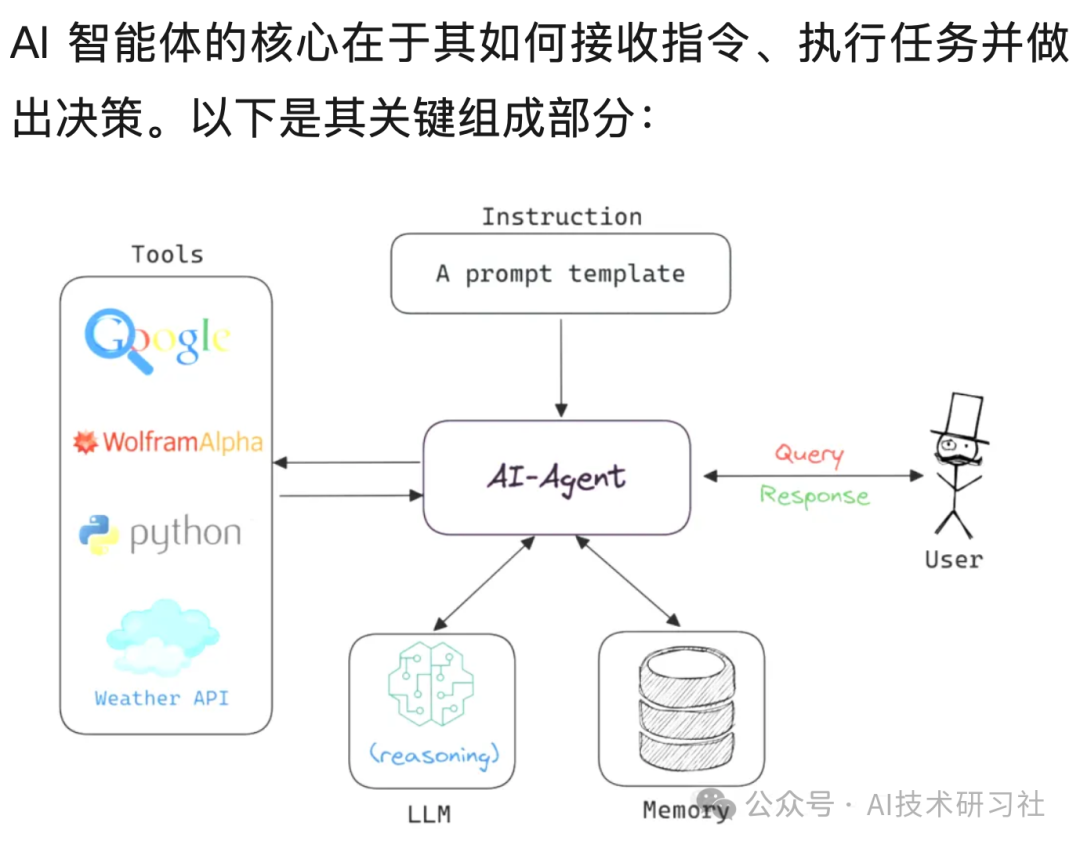
智能体集群(Agent Swarms,简称AS)是Kimi实现复杂任务自动化的核心技术形态。简单来说,它不是让一个AI从头做到尾,而是由一个“主智能体”将复杂任务拆解成多个子任务,动态调度最多100个“子智能体”并行执行,总计可完成1500次工具调用,效率比单智能体方案提升4.5倍-45。
生活化类比:想象你是一家建筑公司的项目经理(主智能体)。过去,你一个人画图纸、搬砖、刷墙,效率极低。现在,你学会了“调度”——把画图交给设计师,砌墙交给瓦工,刷墙交给油漆工,大家同时干活。这就是智能体集群的本质:分工协作,并行推进。
在Kimi K2.5中,这一能力通过 Orchestrator 机制实现——系统自动将用户指令拆解、分配并监控执行,设计了专门的并行RL奖励函数来防止协作退化为串行流程-13-12。
三、关联概念讲解:Token效率
如果说智能体集群解决的是“怎么干”的问题,那么Token效率(Token Efficiency)解决的就是“干得多好”的问题。
定义:Token效率指模型从每个训练Token中学习到的有效智能量。Kimi团队通过自研二阶优化器替代传统Adam优化器,在相同训练数据下,Token学习效率提升2倍——相当于用50万条数据达到其他模型100万条数据的效果-45。
它与智能体集群的关系:Token效率是“地基”,智能体集群是“高楼”。没有高效的Token利用能力,模型无法在有限数据中充分学习规划与推理能力;而Token效率提升后释放的计算资源,又可以分配给更多Agent并行协作,形成正向循环。杨植麟在GTC 2026上明确指出,Token效率、长上下文和智能体集群三个维度并非独立优化,而是要形成乘数效应-12。
| 维度 | 核心作用 | 类比 |
|---|---|---|
| Token效率 | 从单位数据中学习更多智能 | 大脑的学习效率 |
| 长上下文(Kimi Linear) | 一次性处理海量信息 | 大脑的记忆容量 |
| 智能体集群 | 并行执行多任务 | 团队的协作能力 |
一句话记忆:Token效率决定了AI的“智商”能多高,智能体集群决定了AI能“做多大事”。
四、代码示例:通过API调用Kimi完成多步骤任务
下面是一个调用Kimi API实现工具调用(Function Calling)的极简示例:
调用Kimi API实现联网功能 import json from openai import OpenAI client = OpenAI( api_key="你的_MOONSHOT_API_KEY", base_url="https://api.moonshot.cn/v1" ) 定义可用工具 tools = [{ "type": "function", "function": { "name": "web_search", "description": "执行网络获取实时信息", "parameters": { "type": "object", "properties": { "query": {"type": "string", "description": "关键词"} }, "required": ["query"] } } }] 调用Kimi模型,让其决定是否调用工具 response = client.chat.completions.create( model="kimi-k2.5", messages=[{"role": "user", "content": "帮我2026年GTC大会上Kimi的技术亮点"}], tools=tools ) Kimi会输出一个包含工具调用参数的JSON tool_call = response.choices[0].message.tool_calls[0] print(f"Kimi决定调用工具: {tool_call.function.name}") print(f"参数: {json.loads(tool_call.function.arguments)}")
关键步骤解读:第15-22行定义工具,第24-28行发起调用,Kimi大模型会智能判断是否需要调用外部工具,并输出格式化的JSON参数-。这背后依赖的是Kimi K2.5的万亿参数MoE架构和384个专家网络的精准路由能力-22。
五、底层原理支撑
Kimi各项能力的底层依赖三项关键技术突破:
MuonClip优化器:替代沿用十年的AdamW优化器,解决Logits爆炸问题,实现2倍于AdamW的计算效率-13。
Kimi Linear混合线性注意力架构:挑战“所有层必须使用全注意力”的惯例,在128K甚至1M的超长上下文中,将解码速度提升5到6倍-。
Attention Residuals方案:用Softmax注意力替代传统加法累加,解决深层网络中隐藏状态被稀释的问题-13。
这三项创新共同构成了Kimi从“问答工具”向“智能执行体”跃迁的技术底座。
六、高频面试题与参考答案
Q1:Kimi与传统AI助手的核心区别是什么?
参考答案:传统AI助手是被动的“问答机器”,Kimi进化为主动的“智能执行体”,具备三大核心差异:一是多智能体集群能力,可调度100个子Agent并行执行;二是混合线性注意力架构,支持百万级Token的超长上下文;三是端到端工具调用能力,可自主操作浏览器、代码终端等超过20种工具。一句话总结:传统AI“回答问题”,Kimi“完成任务”。
Q2:Kimi Linear注意力架构的技术优势有哪些?
参考答案:Kimi Linear是一种混合线性注意力架构,由三份Kimi Delta Attention(KDA)和一份全局MLA组成。核心优势包括:在超长上下文中解码速度提升5-6倍,KV缓存减少约75%;通过细粒度门控机制实现更精准的记忆管理,让模型能选择性保留重要信息、丢弃冗余信息。这是首个在短上下文、长上下文和RL训练场景下均超越全注意力的线性注意力架构-。
Q3:Token效率为何重要?Kimi如何提升Token效率?
参考答案:有效训练数据是有限的“常量”,Token效率决定了从单位数据中能学到多少智能。Kimi通过自研MuonClip优化器替代传统Adam优化器,在相同训练数据下Token学习效率提升2倍——相当于用50万条数据达到100万条的效果-45。这既降低了算力成本,也为模型能力的持续突破提供了数据效率基础。
Q4:什么是Agent Swarm(智能体集群)?
参考答案:Agent Swarm是Kimi首创的多智能体协作技术。主智能体(Orchestrator)将复杂任务拆解为子任务,动态调度最多100个子智能体并行执行,可完成1500次工具调用,效率比单智能体方案提升4.5倍。关键设计是通过专门的并行强化学习奖励函数防止协作退化为串行,确保真正的并行效率-45。
七、结尾总结
回顾全文,Kimi的核心知识体系可以概括为 “一条主线、三个支点” :主线是“从问答助手向智能执行体演进”,三个支点分别是Token效率(学习效率)、Kimi Linear(记忆容量)和Agent Swarm(执行能力)。学习者最易混淆的是“Token效率”与“推理速度”——前者关乎训练阶段的数据利用率,后者关乎推理阶段的响应速度,两者目标不同但相互影响。
下一篇文章,我们将深入剖析Kimi Linear注意力架构的数学原理,并结合Attention Residuals讲解如何突破Transformer的深度限制,敬请期待。