2026年被视为AI手机爆发年,系统级AI智能体正在成为行业共同演进方向-3。读懂手机AI智能助手背后的技术逻辑,既是跟上技术浪潮的必修课,也是面试备考的核心考点。
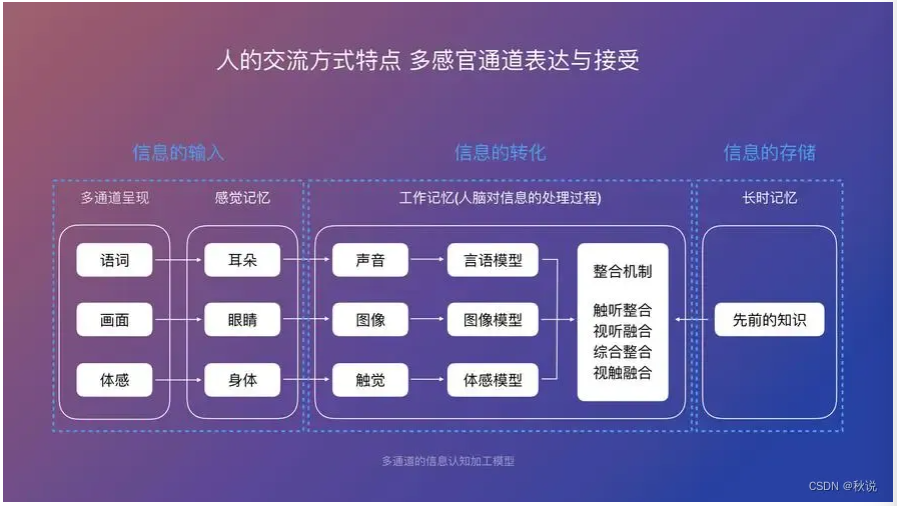
痛点切入:为什么我们需要手机AI智能助手?

在回答这个问题之前,不妨先看看“没有系统级AI”时我们是怎么用手机的。
假设你想“在附近找一家人均200元且有包间的粤菜馆,订今晚7点的位置”。在没有AI智能助手参与的情况下,你需要:打开大众点评 → “粤菜” → 筛选“人均200元” → 逐个看详情判断是否有包间 → 找到符合条件的 → 打电话或在线预订 → 确认。这个过程至少需要5—7步,横跨多个应用页面。

传统手机交互的本质是

操作链路长:完成一个复杂任务需要在多个应用间频繁切换
认知负担重:用户需要熟悉每个应用的操作逻辑
意图传递效率低:自然语言表达的需求需要用户手动“翻译”成一系列操作
上下文无法延续:跨应用操作时,信息无法自动传递
传统的解决方案有两种:一是靠应用内部的“自动化脚本”(如iOS的快捷指令),但需要用户手动配置,覆盖场景有限;二是靠语音助手做简单跳转(如“打开微信”),但无法完成多步骤、跨应用的复杂任务。
核心痛点在于:手机里有强大的计算能力,却没有“理解并执行自然语言指令”的能力。 这正是手机AI智能助手要解决的根本问题。
一、核心概念讲解:什么是手机AI智能助手?
标准定义:手机AI智能助手(Mobile AI Assistant)是深度集成在智能手机操作系统中的AI智能体(Agent),它通过自然语言处理(Natural Language Processing,NLP)、多模态感知和任务规划能力,理解用户以自然语言发出的指令,并自主调用系统能力或第三方应用完成跨步骤的复杂任务。
关键词拆解:
智能体(Agent) :区别传统问答模型的关键。普通大模型是“你问我答”,而Agent是“你发指令,我帮你做完”-69。Agent要能理解任务、拆解步骤、调用工具、根据执行结果动态调整。
系统级集成:区别于普通的“语音助手App”,系统级AI获得了操作系统底层权限,可以调用各应用的API或模拟人类操作界面。
多模态感知:不仅能听懂语音,还能“看懂”屏幕——通过多模态大语言模型对手机界面进行语义理解和操作定位。
生活化类比:如果把手机比作一辆汽车,传统交互模式就像手动挡——每一个操作(挂挡、踩油门、打方向盘)都需要用户亲自完成。而手机AI智能助手就像是车辆的“自动驾驶系统”——你只需要告诉它目的地(“带我去附近的粤菜馆”),它自己规划路线、控制油门刹车、处理路况。
AI智能体正从“外挂式框架”转向“模型原生智能体”,以智能手机助手为代表的嵌入式智能体硬件,能够实现设备内多应用调用、跨设备操作等功能-3。
二、关联概念讲解:ASR、NLU、NLG —— AI助手的“听说读写”
要实现真正的“智能助手”,光有意图理解还不够。完整的手机AI智能助手背后,是一个环环相扣的技术流水线。
ASR(Automatic Speech Recognition,自动语音识别) :将用户的语音输入转换成文本。当前主流的ASR系统普遍采用端到端深度学习架构,在安静环境下字错率已低于5%-10。
NLU(Natural Language Understanding,自然语言理解) :解析文本的意图和关键信息。包括领域识别(判断属于音乐、天气还是设备控制)、意图识别(确定是询问、指令还是闲聊)与槽位填充(提取关键参数,如时间、地点)-10。基于BERT等预训练模型的NLU系统,准确率可达90%以上-10。
NLG(Natural Language Generation,自然语言生成) :根据处理结果生成自然、流畅的语言反馈给用户-12。
这三个环节的关系可以这样理解:ASR解决“听清”,NLU解决“听懂”,NLG解决“说清”。
三、概念关系与区别总结
| 概念 | 核心任务 | 输入 | 输出 | 定位 |
|---|---|---|---|---|
| AI智能体(Agent) | 理解任务 + 规划执行 + 调用工具 | 自然语言指令 | 任务完成状态 | 顶层决策者 |
| ASR | 语音→文本 | 音频流 | 文字 | 感知层 |
| NLU | 文本→意图+参数 | 文字 | 意图/槽位 | 理解层 |
| NLG | 意图→自然语言回复 | 意图/数据 | 自然语言 | 表达层 |
一句话概括:AI智能体是“大脑”,ASR是“耳朵”,NLU是“理解中枢”,NLG是“嘴巴”——它们共同协作,完成从“听到”到“做到”的完整闭环。
四、代码/流程示例演示
以下是一个简化版的手机AI智能助手核心流程示意(以Android平台为例,使用伪代码说明核心逻辑):
// 1. 语音输入与识别(ASR) fun handleVoiceCommand(audioData: ByteArray) { // 调用系统语音识别服务 val text = speechRecognizer.recognize(audioData) // 2. 自然语言理解(NLU)——意图识别与槽位提取 val intent = nluEngine.analyze(text) // 示例:text = "帮我点一杯manner的白脱拿铁,送到公司" // intent = { domain: "外卖", action: "下单", slots: {brand:"manner", product:"白脱拿铁", address:"公司"} } // 3. 任务规划(Agent Planning)——思维链分解 val steps = agentPlanner.decompose(intent) // steps = [打开外卖App, 品牌门店, 选择商品, 确认地址, 下单支付] // 4. 执行与反馈循环 for (step in steps) { // 4a. 屏幕感知(GUI Grounding) val screenState = captureScreen() val targetElement = multimodalModel.locateElement(screenState, step.target) // 4b. 模拟操作执行 executeAction(targetElement, step.action) // 4c. 等待并验证结果 waitForScreenChange() if (!verifyStepComplete()) { // 异常处理:重试或重新规划 replan(step) } } // 5. 结果反馈(NLG) speak("已为您下单成功,预计30分钟送达") }
关键步骤标注:
ASR:通过系统级API调用语音识别能力,将音频转为文本
NLU:利用预训练语言模型(如BERT)进行意图分类和实体抽取
任务规划:利用思维链(Chain of Thought)技术将模糊指令拆解为原子化任务序列-11
GUI Grounding:多模态大模型“看懂”屏幕UI,将按钮图标映射为可操作的坐标参数-11
执行闭环:通过Android Accessibility API模拟点击滑动,并持续监测屏幕反馈动态调整-11
新旧对比:
传统方式:用户手动操作7步 → 耗时约60秒
AI智能助手方式:用户一句话指令 → 系统自主执行 → 耗时约15秒,且全程无需用户介入
五、底层原理与技术支撑
手机AI智能助手的技术突破,依赖以下几个核心支撑:
1. 端侧大模型(On-Device LLM)
传统AI助手依赖云端大模型,存在延迟高、隐私风险、离线不可用等问题。2026年的突破在于:端侧大模型已能在普通手机上高效运行。
谷歌Gemma 4:专为低功耗设备设计,最小模型只需3.2GB内存即可运行,原生支持函数调用和结构化输出-29-30
腾讯混元HY-1.8B-2Bit:通过2Bit量化技术,等效参数量仅0.3B,内存占用600MB,生成速度提升2-3倍-32
苹果Ferret-UI Lite:30亿参数的轻量级多模态模型,专为手机UI理解设计-31
2. 多模态大语言模型(MLLM)
这是AI智能助手“看懂屏幕”的技术基础。多模态模型像人类视觉一样去“看”屏幕,利用计算机视觉与语言模型的结合,对UI界面进行语义分割和理解-11。其核心能力是GUI Grounding——把视觉上的按钮图标映射为可操作的坐标参数。
3. 硬件加速(NPU)
现代智能手机普遍搭载专用AI芯片(如华为麒麟NPU、高通Hexagon)。端侧模型推理通过这些NPU加速,可在毫秒级完成计算,同时保持低功耗。以Android NNAPI为例,在支持NPU的设备上可实现15ms/token的推理速度-66。
4. 系统级权限与无障碍服务(Accessibility API)
AI智能体要“代替用户操作手机”,需要调用操作系统底层接口。Android的Accessibility API允许应用模拟点击、滑动、文本输入等操作,这是实现跨应用自动化的关键技术桥梁-11。
六、高频面试题与参考答案
Q1:手机端AI Agent和普通云端大模型问答的最大区别是什么?
参考答案:普通大模型问答是“你问我答”,核心是根据上下文生成自然语言。而AI Agent更像一个“会做事的系统”,除了生成文字,还要能理解任务、拆解步骤、调用工具、读取外部信息、根据执行结果继续往下走。在手机端场景中,Agent还要接系统能力、应用能力和设备能力,重点不是“模型会不会说”,而是“模型能不能在复杂任务里做对决策”-69。
踩分点:对比式回答(问答vs做事)→ 点出“理解-规划-执行”闭环 → 强调手机端特殊约束(资源、权限)
Q2:手机端AI Agent的整体架构怎么设计?
参考答案:可以拆成五层架构——从上到下依次为:①用户交互层(接收语音、文字、多轮上下文);②意图理解与任务路由层(判断是直接问答、知识检索还是多步任务);③规划层(把复杂任务拆成可执行步骤);④工具层(接、日历、短信、地图、系统设置等能力);⑤执行与观测层(日志、超时、重试、权限控制、结果回收)。实际落地时通常做成“规则+小模型+大模型+工具调用”的混合方案,而不是完全依赖大模型-69-68。
踩分点:分层清晰 → 强调混合方案而非全依赖大模型 → 点出手机端特殊考量(延迟、功耗)
Q3:端侧大模型和云端大模型在手机AI助手中分别承担什么角色?
参考答案:端侧主要负责快速响应、涉及隐私及离线场景的任务——包括语音唤醒、简单问答、手机操作控制、文本创作与摘要、日常提醒等,确保数据不离开本地以保障隐私安全。云端则负责需要强大通用知识的复杂任务,如复杂推理、长文生成、实时信息检索等。端云结合是当前的主流服务模式--2。
踩分点:区分端侧/云端的职责边界 → 强调隐私与性能权衡 → 点出“端云结合”趋势
Q4:什么是GUI Grounding?在AI手机中起什么作用?
参考答案:GUI Grounding是指多模态大语言模型将手机屏幕上的UI元素(按钮、图标、文本)映射为可被计算机操作的坐标和动作的过程。当AI智能体决定操作某个App后,多模态模型会实时截取屏幕画面,像人类视觉一样“看”屏幕,通过语义分割识别“加入购物车”、“确认下单”等按钮,将其转化为点击坐标。这是AI实现“模拟人类操作界面”的核心技术-11。
踩分点:准确定义 → 说明技术原理(视觉+语义映射) → 强调在跨应用自动化中的关键作用
Q5:如何保障手机AI智能助手的用户隐私安全?
参考答案:主要从三个维度保障:①端侧处理——敏感数据(如屏幕截图、语音指令)尽量在本地完成推理,不上传云端。以豆包AI手机为例,屏幕内容不会在云端存储,也不进入模型训练-11;②权限最小化——敏感操作(如支付)需用户手动确认,AI不代替用户进行授权-11;③安全隔离(TEE) ——利用硬件可信执行环境对生物特征等敏感数据进行隔离保护-68。
踩分点:分点作答 → 端侧隐私、权限控制、硬件隔离三方面 → 可引用实际案例增强说服力
七、结尾总结
回顾全文,我们从“为什么需要手机AI智能助手”出发,梳理了从痛点识别到概念定义、从核心流程到代码实现、从底层原理到面试考点的完整知识链路。
核心要点回顾:
手机AI智能助手的本质是从“指令驱动”向“意图驱动”的交互范式转变
其技术栈涵盖ASR、NLU、NLG、多模态感知、任务规划等多个层次
端侧大模型的轻量化突破(如Gemma 4、混元0.3B)使AI能力可以本地运行,兼顾隐私与性能
2026年AI手机渗透率在中国市场将首次过半,系统级AI智能体已成为行业共识方向-2
易错点提醒:
不要混淆“AI智能体(Agent)”与“大语言模型(LLM)”——Agent是系统架构,LLM是其中一种能力组件
不要将“手机AI助手”等同于“语音助手”——前者具备跨应用自动化执行能力,后者通常仅限于问答和简单跳转
下期预告:下一篇我们将深入解析GUI Agent与A2A两条技术路线的差异与演进,对比“模拟人类操作界面”与“应用间协议互联”两种方案各自的优劣与适用场景,敬请期待。
本文基于2026年4月10日的行业动态撰写,数据来源包括IDC、Sensor Tower等权威机构。技术示例仅供参考,实际实现以具体平台SDK为准。